The equation of any of the flow modes available can be re-written in residual form as:
\[R(X)=0,\]
\(X\) being a set of primary independent pressures and saturations which describe the state of the reservoir. Not all phase saturations are independent of course, as they must sum to unity, so we take the first \((N_p-1)\) saturations as primary variables, where \(N_p\) is the number of phases present. In the case in which we have dissolved gas, the variables \(\{P,P_b,S_o\}\) will substitute for \(\{P,S_g,S_o\}\) in the case of saturated cells (in which all the surface gas present is dissolved in the reservoir oil, as described in the section on the black oil model.
Define the Jacobian as \(J= \frac{dR}{dX}\), and a single Newton iteration is then an update to \(X\) of the form:
(1)\[\begin{split}\begin{split}
&\Delta X=J^{-1}R(X); \\
&X:=X+\Delta X
\end{split}\end{split}\]
where \(J\) is the Jacobian, a matrix with dimension equal to the total number of degrees of freedom of the problem.
For fully implicit reservoir simulation, the Jacobian matrix which has to be inverted by the linear solver (1) is typically a non-symmetric diagonally-dominant matrix which can be viewed as a set of \(N_c\) by \(N_c\) sub-matrices, \(N_c\) being the number of components in the problem, and energy, if modelled, equal to the number of variables associated with each simulation cell.
The usual approach is to precondition the linear system, and solve it iteratively within an acceleration system such as GMRES [CB+01]. These systems construct a Krylov space by repeatedly applying a matrix to a vector, and then build a solution which yields the minimum residual vector within that space. If the set of equations to be solved is:
\[Ax=b\]
with \(A\) an \(N\) by \(N\) square matrix, \(x\) a solution vector and \(b\) a right-hand side vector, then the Krylov space would simply be: \(\mbox{span}\{b,A.b,A^2 b,\ldots\}\). Such a method will yield an exact solution in N steps, and so could be used as a rather inefficient direct solver (it is rarely used in this manner).
If a preconditioning matrix, \(B\), is introduced, then it is possible to solve the equivalent system:
\[B^{-1}A.x=B^{-1}b\]
The Krylov space is then \(\mbox{span}\{B^{-1}b, B^{-1}AB^{-1}b,\ldots\}\). \(B\) is usually chosen as an easily invertible approximation to \(A\).
The GMRES solution is developed as the construction of a sequence of search directions, each one being orthogonalized against the previous set of search directions. If the matrix is symmetrical, this stack truncates to one previous value, and this yields the classical Conjugate Gradient method. For the general non-symmetric case, the stack can be truncated or the iteration periodically restarted. A further alternative is to treat a larger symmetric system such as the matrix and its transpose. This yields a class of BiCG methods, which allow the use of a single-element stack, at the expense of monotonic convergence in the linear residual norm. Many of these methods, including BiCG, are available in PETSc. For the general non-symmetric case the GMRES iteration may be periodically restarted. In some cases in which the effective pre-conditioning varied from iteration to iteration and alternative to GMRES called FGMRES may be used.
There are a large number of alternative iterative methods and preconditioning techniques available in the PETSc library which underlies PFLOTRAN-OGS. However, for difficult heterogeneous cases the combination of AMG/CPR preconditioning with GMRES acceleration has proved reliable and effective. The AMG (algebraic multigrid) is described below.
Suppose that the basic system is two-phase, as in the isothermal TOIL case, so each cell contains a pressure and an oil saturation variable. The default solver in PFLOTRAN-OGS is an incomplete lower-upper factorisation (ILU) method. When the ILU solver is used on its own, some problems can prove very difficult to solve, for example the SPE10 test cases of [CB+01]. The solution is to use a two-stage solver within the GMRES structure. At each iteration, an AMG step and then a block Jacobi step is used.
This solver uses diagonal pivoting to eliminate saturation variable couplings from the first component diagonal term and to form a set of linear equations in just the pressure change. Note that in general this diagonal pivoting does not eliminate all the saturation variable couplings from the off-diagonal band terms, and some of these are dropped in order to form a pressure equation.
The pressure equation then repeatedly coarsened into a stack of levels. A typical solution pattern is a V-cycle going from the finest to the coarsest level and back again, with Jacobi or Gauss-Seidel smoothing. The Jacobi smoother is parallelisable whilst the Gauss-Seidel is not, so Jacobi is the default. Smoothing is performed in both directions of the V-cycle, the pattern being:
At level L:
Do smoothing to obtain solution change at this level
Find residual change on this level
Coarsen the resulting residual and push to next level
Call level L+1
Interpolate the solution change and pull back to this level
Find residual change on this level.
Do smoothing again to obtain full solution change at this level
The AMG algorithm in Petsc which is available in PFLOTRAN-OGS is the Hypre implementation.
In PFLOTRAN-OGS’s input deck this two stage AMG based solver is referred to as a CPR
(“compressed pressure residual”) preconditioner after the literature.
As an interesting diversion, it is possible to visualise the effect of a simple multigrid
algorithm on a trivial model to see how the different levels affect different “types” of error,
and thus how the combination of fine and coarse level corrections is is so effective.
We consider a trivial one dimensional Laplacian equation with 0 RHS, discretised with finite
differences. The true solution to this is 0 on every node, and we will attempt to get to this
solution using Gauss-Seidel iterations. However we will start with the following initial guess
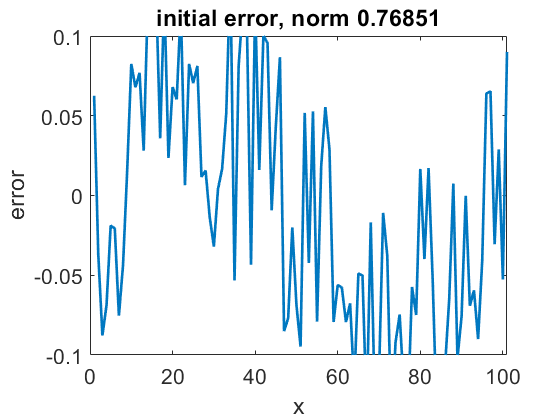
(and thus initial error):
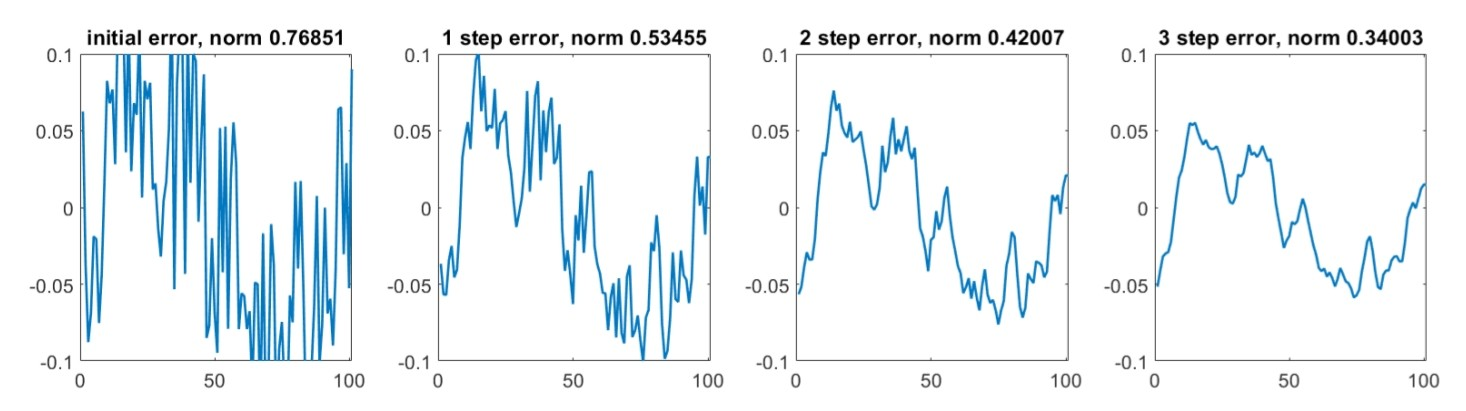
This is a sum of a sinusoidal wave over the domain, and random noise. The sinusoidal wave part of the error is an example of “long range” or long wavelength error, while the noise is an example of “short range” or short wavelength error. The difference becomes significant when we try applying a few GS sweeps to improve the solution:
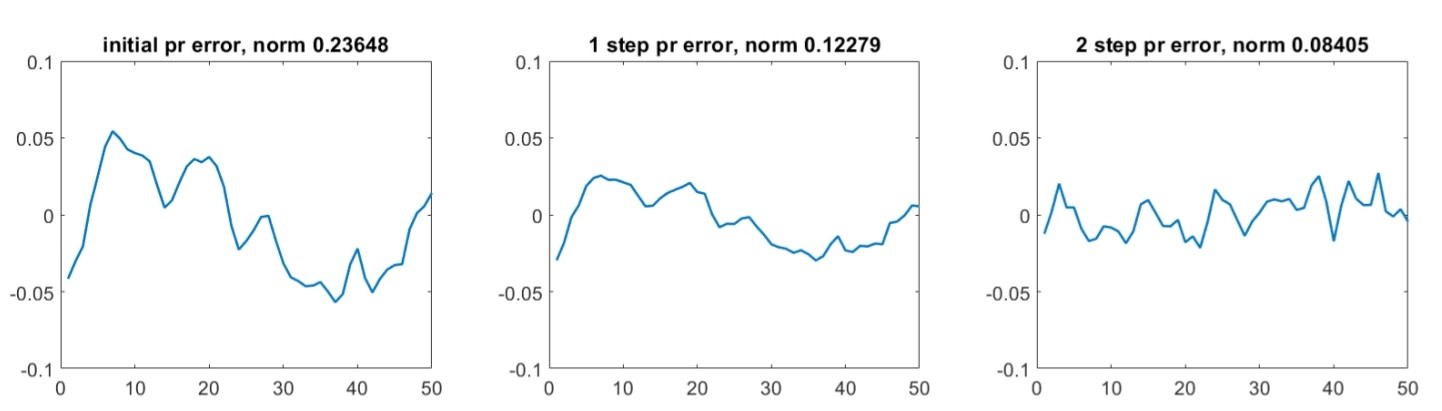
We see the noise part of the error is reduced with ease, but the sinusoidal wave part is not. We next try generating a coarser grid (as this is a uniform 1D grid, we just remove half the nodes) from the existing one, and projecting the solution we have onto it, and applying more GS sweeps:
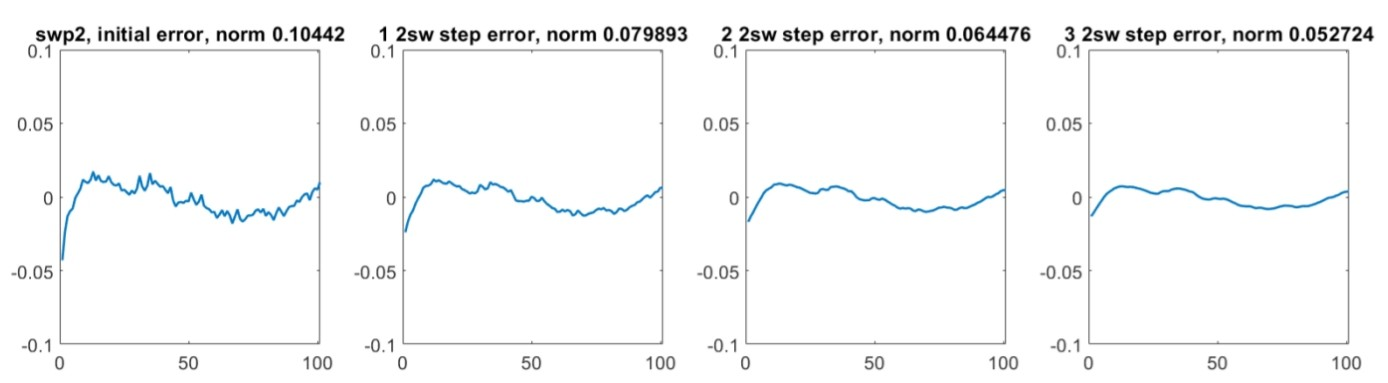
The coarse grid does nothing to reduce the remaining noise error, but is remarkably effective at smoothing out the sinusoidal wave part of the error. Finally we interpolate the solution back to the original grid (thus completing a very simple V-cycle) and try more GS sweeps to control the remaining noise error:
Though of course artificial and heavily engineered, this example provides an intuitive, if not rigorous, way to think about multigrid techniques. Error may thought of as a combination of long and short wavelength components. Classical relaxers such as Gauss-Seidel tend to be better at smoothing out short wavelength error components but have little effect on long wavelength ones. Projecting a solution onto a coarser grid can effectively make long wavelength components into short wavelength ones (and short wavelengths errors effectively invisible, so a fine grid does have to be used at some point). Thus a combination of fine and coarse grid correction often works very well.
The above is an example of geometric multigrid, in that levels of explicit grids were generated and used. In the more methodology of algebraic multigrid, different levels of linear systems are algebraically created instead of explicit grids, allowing much greater flexibility of implementation and applicability. The same relationship between the levels and types of error is the basis of algebraic multigrid.